RAG ломается раньше, чем кажется
1. RAG ломается раньше, чем кажется
Потолок начинаешь чувствовать раньше, чем его получается измерить. На нескольких сотнях тысяч документов хорошо настроенный векторный индекс начинает промахиваться на запросах, на которые отлично отвечал при нескольких тысячах. Добавляешь реранкер — top-1 возвращается. Добавляешь гибридный поиск — длинный хвост выравнивается. Растёшь дальше — и отказы возвращаются, те же по сути, только воспроизвести их сложнее. Большинство команд читает это как задачу тюнинга. Weller и соавторы (ICLR 2026) объясняют иначе: у одновекторного ретривера есть репрезентативный потолок, и выше него никакие ухищрения в конце пайплайна уже не помогают.
Мой собственный стек упёрся в этот потолок раньше, чем я прочитал его объяснение, и вики, которая его заменила, выросла из реакции, а не из плана.
Часть 1 проходит по местам, где плоский RAG ломается, со ссылками на исследования. Часть 2 — архитектурная альтернатива, LLM Wiki Karpathy, и почему она переформулирует пайплайн как компиляцию, а не как поиск. Часть 3 — другие системы, делающие тот же манёвр в разных формах: системы агентной памяти, граф-RAG, HippoRAG. Часть 4 — где вики оказывается неправильным ответом. Часть 5 — что ломается первым, когда её действительно строишь, из опыта сборки хранилища для команды AI-инфраструктуры.
Weller и соавторы (ICLR 2026) записывают потолок как неравенство. Для корпуса из документов, top- запросов и зазора score размерность эмбеддинга должна удовлетворять условию . Ниже этой границы часть top- комбинаций просто нельзя представить в векторном пространстве. Граница работает в одну сторону: если размерность эмбеддинга ниже порога для этого размера корпуса, ни реранкер, ни гибридный поиск, ни промпт-инжиниринг не вытащат пропущенные комбинации. Геометрия уже неправильная.
Дальнейшие режимы сбоя ложатся в три слоя. Геометрия (потолок выше): структура, её тюнингом не сдвинуть. Чанкинг и утилизация контекста: вопрос бюджета — аккуратная предобработка лечит, но сами бюджеты усыхают. Внимание и hard-negatives: провалы на стороне генератора, лучшими промптами лечатся, пока промпты вообще работают. Геометрию тюнингом не сдвинуть. Остальные два слоя поддаются инженерной работе.
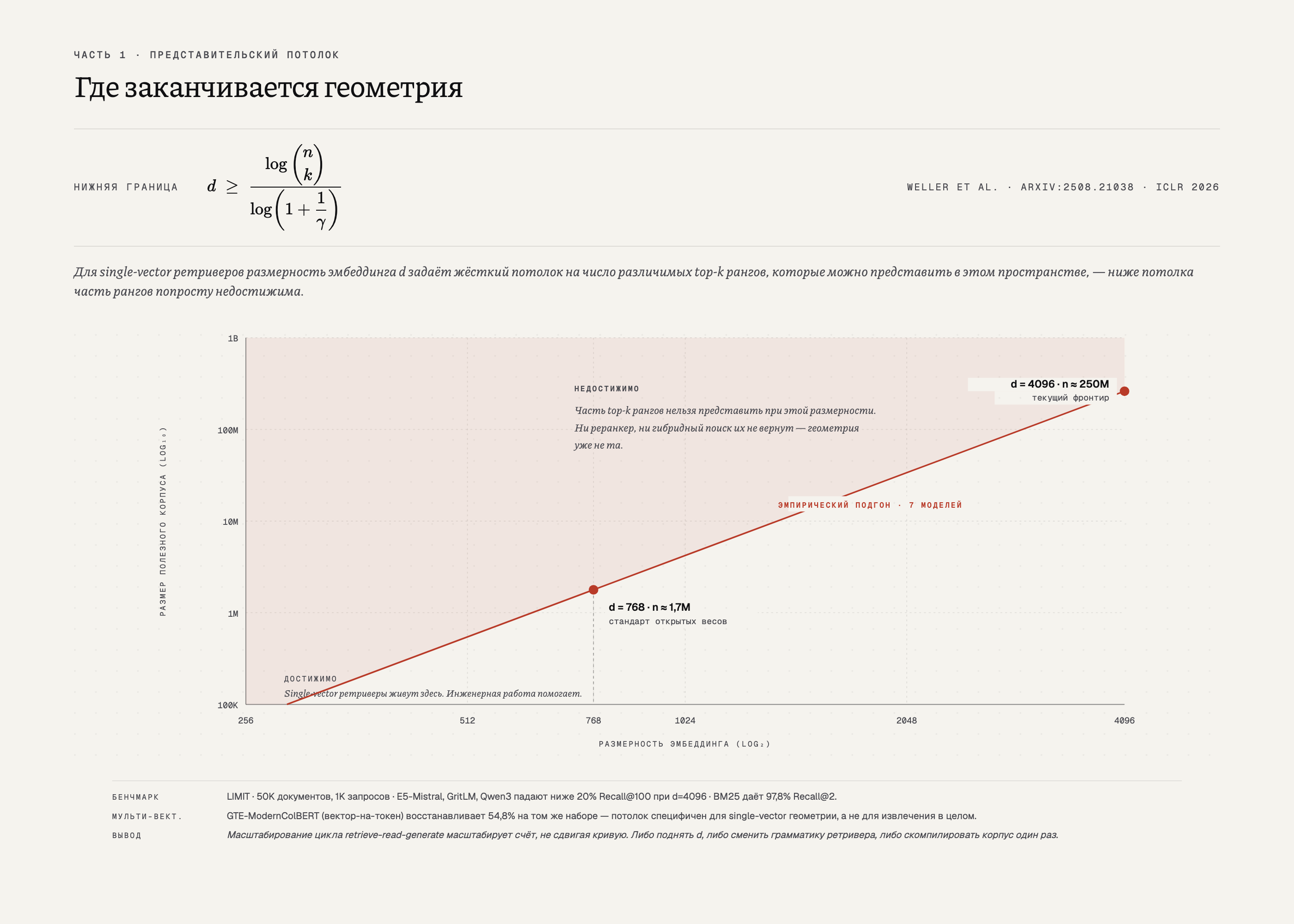
На практике разрыв между теоремой и реальностью оказывается меньше, чем хотелось бы. Потолок полезного корпуса — в районе 250 миллионов документов при 4096 измерениях и около 1,7 миллиона при 768 (до сих пор стандарт для открытых моделей). Выше этих объёмов часть top--комбинаций уже вне досягаемости любого вектора, построенного ретривером.
Большинство бенчмарков на эту границу не выходят. LIMIT — выходит. Пятьдесят тысяч документов, тысяча запросов, предложения типа «Jon likes apples». Лучшие эмбеддинг-модели падают ниже 20% Recall@100 при 4096 измерениях. BM25 выдаёт 97,8% Recall@2. Проблема в геометрии одного вектора: обученный эмбеддинг представляет конечное число top- наборов, и когда запрос выпадает из этого набора, ничего дальше по цепочке ситуацию не исправляет.
Следующим ломается чанкинг, и весит он столько же, сколько выбор модели. Исследование Vectara (arXiv:2410.13070) ставит вопрос, окупается ли семантический чанкинг, и на F1@5 отвечает: в большинстве сценариев не окупается — ретривер выигрывает на recall, генератор проигрывает на локальном контексте, и два эффекта гасят друг друга. Провал обычный: чанки достаточно мелкие для точного поиска оказываются слишком мелкими, чтобы по ним ответить.
Аттеншн обычно недооценивают. Больше половины сниппетов можно выкинуть без ущерба для ответа (arXiv:2511.17908). Работы, на которые эта статья опирается — RULER и исследования Context Rot — оценивают полезный срез 128k-токенового контекста в 10–20% от номинала. Модель скользит по поверхности. Смещение по позиции зашито в архитектуру. Разбор MIT (arXiv:2502.01951) даёт механизм: каузальная маска копит внимание на первых токенах, а rotary embeddings добавляют долгосрочное затухание в score. Независимая эмпирика на длинных контекстах (RULER, Context Rot) подтверждает эту форму на практике — середина контекста недоучитывается, и длинное окно не прибавляет внимания; лишние токены попадают в зону, которую модель и так пропускает.
Ошибки складываются. Hard-negative документы — похожие-но-не-те, которые хороший ретривер и должен находить — ухудшают итоговую точность. А случайные несвязанные документы её улучшают, примерно на 35%. Починка одной проблемы обычно вскрывает следующую.
Улучшения есть, и все настоящие. Contextual Retrieval переписывает чанки с учётом окружающего контекста перед эмбеддингом: –35% провалов на одних эмбеддингах, –49% с BM25, –67% с реранкером сверху. GraphRAG ставит в приоритет саммари сообществ и платит за это индексацией, достаточно дорогой, что Microsoft сам выпустил LazyGraphRAG как дешёвое продолжение, совпадающее по качеству примерно за 1/700 стоимости запроса. Self-RAG и CRAG переносят политику извлечения внутрь самой модели. Ни одно из этих улучшений не меняет базовый цикл: эмбеддинг, поиск, чтение, генерация. Каждый запрос проходит цикл заново, платя полную цену.
RAG — правильный первый ответ на вопрос «как прицепить LLM к своим данным». Для прототипа, PoC, первой интеграции он работает, стоит недорого и даёт форму задачи. Ломается, когда на нём пытаются держать продукт. Цикл эмбеддинг-поиск-чтение-генерация платит полную стоимость извлечения на каждый вопрос и упирается в тот же потолок, где упирается геометрия; масштабирование цикла масштабирует счёт, а не потолок.
Отсюда две ветки. Одна продолжает улучшать цикл в момент запроса: реранкеры, late interaction (ColBERT и наследники), гибридный поиск, обучаемые политики извлечения. Ветка продуктивна, и публичной работы там больше. Другая ветка устроена иначе. Вместо того чтобы платить за извлечение, чанкинг и внимание на каждом вопросе, корпус один раз компилируется во что-то, чем модель может пользоваться сразу. Вся работа делается заранее, в момент поступления источника.
Все эти режимы стоят на одном допущении: корпус остаётся сырым, и модель каждый раз заново выводит, что с ним делать. Альтернатива — скомпилировать корпус один раз в артефакт, который модель читает напрямую, и заплатить за работу при загрузке, а не при каждом запросе. Karpathy в апреле 2026 года опубликовал гист, где назвал эту вторую ветку LLM Wiki. Дальше — что это значит архитектурно и три очень разные системы, которые уже её отгрузили.
2. Вики переносит работу на другой конец цикла
The wiki is a persistent, compounding artifact. Instead of just retrieving from raw documents at query time, the LLM incrementally builds and maintains a persistent wiki.
Я прочитал этот гист в воскресенье и перечитал дважды, пытаясь понять, где подвох. Записка короткая. Вся механика помещается на одну страницу.
У вики три слоя.
- Сырые источники внизу: PDF, расшифровки, заметки, клиппинги с веба. После сохранения не меняются.
- Сама вики в середине: markdown-страницы, которые LLM пишет, по одной на концепцию или решение, связанные вики-ссылками.
- Схема сверху: CLAUDE.md, AGENTS.md, любой файл с описанием того, зачем эта вики. LLM читает его перед каждым действием.
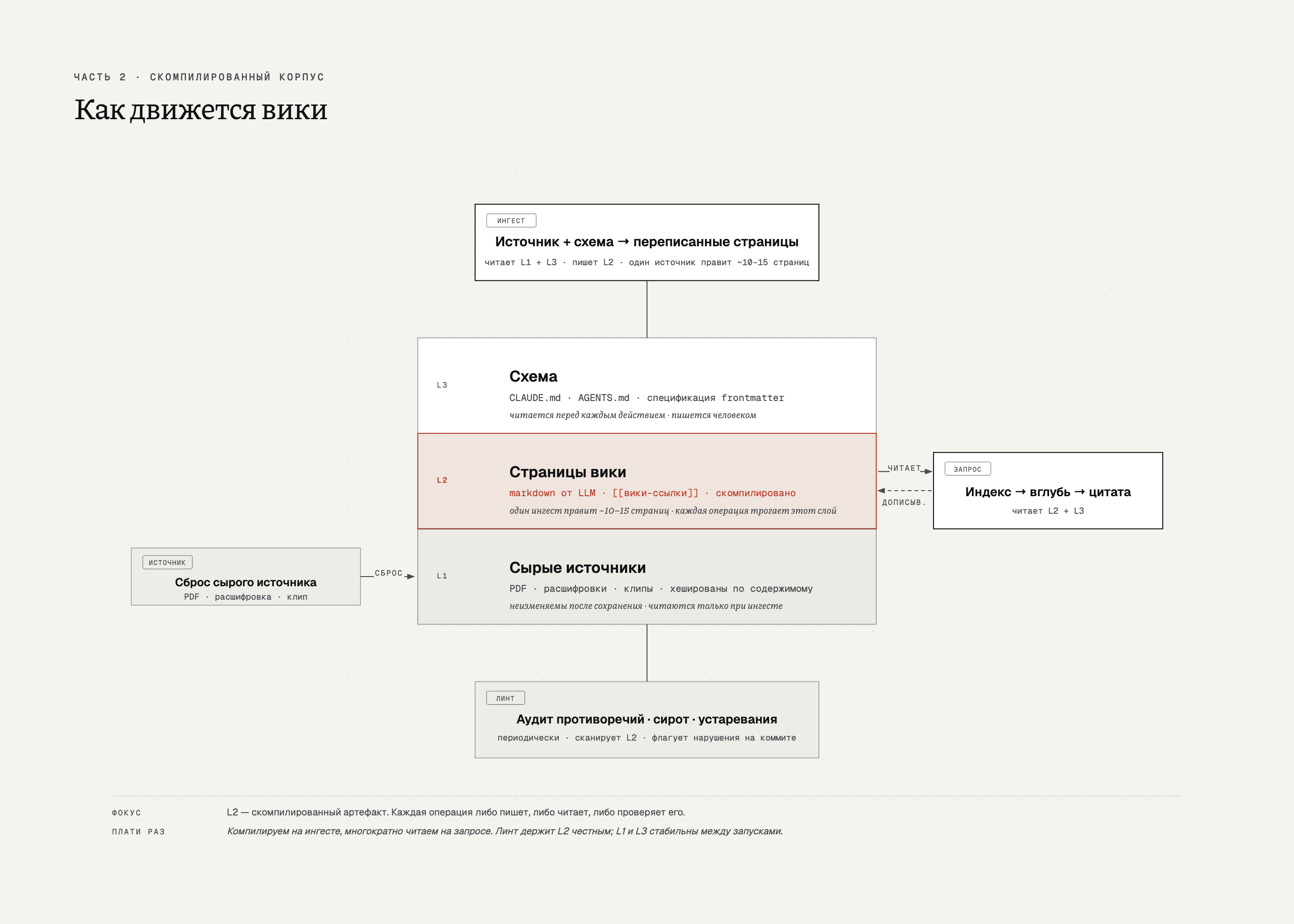
Основную работу делает ингест. Приходит источник, LLM читает его вместе со схемой и индексом и правит страницы, которых источник касается, часто десять-пятнадцать за раз. Формально запрос проще: прочитать индекс, нырнуть в несколько страниц, ответить с цитатами. На деле запрос тоже пишет обратно: если ответ стоит того, чтобы его сохранить, он становится новой страницей, и запрос запускает маленький вторичный ингест.
Поиск тут вторичен. Karpathy прямо пишет, что index.md, простой markdown-каталог, который LLM ведёт сама, для большинства проектов хватает (сотни источников, несколько сотен страниц) и снимает потребность в эмбеддинг-стеке. Векторы можно добавить, когда каталог перестанет справляться. До тех пор они не нужны.
Гист строится на аналогии с компиляцией. Источники на входе, вики на выходе, каждый ингест — инкрементальная сборка поверх предыдущего артефакта. Один источник обычно затрагивает несколько страниц. Через несколько ингестов каждая страница вбирает данные из разных источников, и результат перестаёт быть похожим на пересказ отдельного документа. Генератор работает по скомпилированным страницам, а не по сырому тексту. Главная мысль гиста в двух строчках: «The human’s job is to curate sources, direct the analysis, ask good questions, and think about what it all means. The LLM’s job is everything else» и «Most people abandon wikis because maintenance burden grows faster than value. LLMs don’t get bored.»
Первая операция, которую я попытался продумать, был линт — обход вики в поисках противоречий, устаревших утверждений, сирот и сломанных ссылок. Я знал, что первая написанная мной вики окажется неправильной в местах, которые я сам не замечу. У Karpathy линт описан неформально: запускай периодически, читай отчёт. На деле интересный вопрос в том, когда его запускать и что он делает, когда что-то находит. Гист оставляет это на читателя. Каждая реальная реализация выбирает свои ответы; мои (валидация фронтматтер-схемы на коммите, линтер, флагующий только значения в бэктиках, append-only-лог) — в Части 5.
Karpathy ссылается на «Мемекс» Вэнивара Буша (1945) как на предшественника. «Мемекс» был задуман как личное курируемое хранилище знаний с ассоциативными связями между документами. Одна система, один человек, свои источники.
Исходная спецификация игнорирует время. Она считает любой контент одинаково верным навсегда, а реальные знания так не работают. Очевидное расширение — прикрутить жизненный цикл. Факты получают оценку уверенности, и она убывает без обращений: утверждение, к которому никто не возвращается, теряет доверие само. При замене старая версия остаётся с обратным указателем. Рёбра между страницами типизированы (зависит от, противоречит, замещает), и по ним можно строить структурные запросы. Можно узнать, что вики считала верным в любой момент в прошлом. Файл схемы тут главный. Без него LLM не знает, как себя вести.
Всё это ничего не стоит, пока идея существует только в гисте. Она уже запущена как минимум три раза, на разных платформах, и интересно не то, что они все работают, а то, куда каждая перекладывает работу.
Бюджетная версия
Bash-скрипты поверх Obsidian-волта. Горстка агентов, набор навыков и никакой билд-системы, кроме контракта на то, какие инструменты каждый агент может использовать. Каждый агент объявляет свои примитивы из фиксированного набора — одному, например, разрешено читать страницы и писать индекс, но запрещено трогать файл схемы. Запросит что-то за пределами списка — сборка упадёт. Эта конструкция почти ничего не перекладывает на ингест: агенты собирают по запросу, и работы примерно столько же, сколько без вики вообще. Первым ломается кросс-платформенный рассинхрон. Одно хранилище на несколько LLM CLI держится только потому, что контракт достаточно узкий, чтобы не наступать на различия в интерфейсах.
Тяжёлый подход
Упаковывает всё в десктопное приложение. Tauri-рантайм с React-фронтендом, установочные бинарники для трёх основных платформ. Сюда на ингест перекладывается больше всего работы. Приходит источник, и конвейер ингеста прогоняет двухшаговый chain-of-thought: сначала аналитическое чтение источника на фоне текущего файла целей и индекса, затем генерация типизированных FILE-блоков для всего, что источник затрагивает. Ингест привязан к хешу содержимого, так что повторный ингест ничего не делает, а задания проходят через персистентную очередь с перезапуском. Опциональный векторный поиск прикручен в конце. Весь этот ингест нужен ради одного: вики уже скомпилирована к моменту, когда ты открываешь приложение. Архитектура заточена под один сценарий: очередь не должна терять состояние при сбое.
Портативная версия
Плагин. Одно Agent Skills определение, которое запускается на любом крупном LLM CLI без этапа сборки. Всё держится на одном маленьком markdown-файле — горячем кэше в несколько сотен слов, хранящем свежий контекст текущей работы. В начале сессии он читается, в конце обновляется, и непрерывность держится именно на этом промежутке. Без него каждая новая сессия начинается с амнезии. Кэш протухает, если работа переключается между контекстами без обновления в конце сессии, и ничто в системе этого не замечает.
3. Другие формы того же манёвра
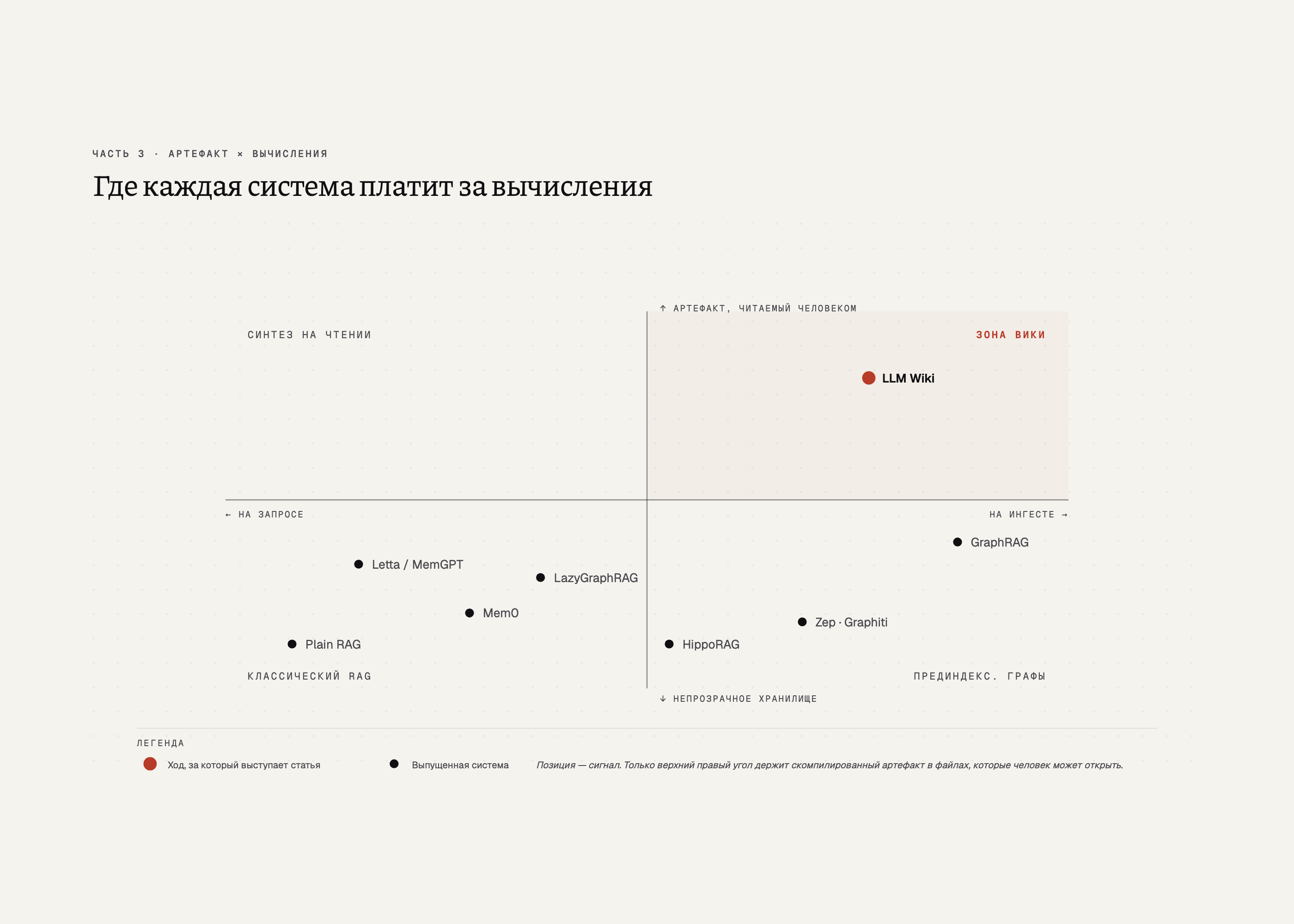
Три системы из Части 2 делают один шаг — компилируют корпус в markdown и отдают артефакт человеку. Остальные решают ту же задачу с другой стороны, и то, что они сохраняют как артефакт, говорит столько же, сколько их механика. Четыре семейства стоит назвать.
Агентные системы памяти: Letta и Mem0
Letta (бывший MemGPT, arXiv:2310.08560) переключает данные между основным контекстом, recall-хранилищем и архивом через function call. Mem0 извлекает факты entity-and-relation из каждого сообщения, разрешает конфликты и пишет в гибридное хранилище (вектор + граф); на LOCOMO он показывает 66,9% точности против 52,9% у памяти OpenAI (статья Mem0, arXiv:2504.19413), сокращая разрыв до full-context-бейзлайна примерно до шести пунктов.
Временны́е графы: Zep
Zep делает самое интересное в этой группе. Его графовый слой, Graphiti (arXiv:2501.13956), ставит временны́е метки valid_at и invalid_at на каждое ребро. Старые убеждения остаются в хранилище с явным сроком годности. Запрос может спросить, что система считала верным в прошлый вторник. Тот же вопрос, на который отвечает расширение жизненного цикла в вики, только со стороны базы данных.
Граф-RAG: линия Microsoft
Граф-RAG-системы стартуют дорого. GraphRAG от Microsoft (arXiv:2404.16130) извлекает граф сущностей, запускает Leiden-кластеризацию и заранее пишет саммари сообществ на каждом уровне — стоимость индексации становится запретительной на чём-то большем одной книги. Собственный follow-up Microsoft, LazyGraphRAG (блог Microsoft Research, ноябрь 2024), выкидывает предварительную суммаризацию и даёт то же качество более чем в 700 раз дешевле на запрос. Это Microsoft Research признаёт, что их собственный индексационный пайплайн был расточительным. LightRAG (arXiv:2410.05779) рядом: извлечение сущностей и отношений на ингесте, двухуровневый поиск, небольшой расход на один запрос по дизайну.
Концептные графы: HippoRAG
HippoRAG (arXiv:2405.14831) — самый странный из всех. Он превращает корпус в концептный граф из именных групп и отвечает на запросы, прогоняя Personalized PageRank. Multi-hop-рассуждение за один шаг. Провал v1 — entity-centric-индексация: концептный граф срезал окружающий контекст и на ингесте, и на инференсе, что било по обычному факт-поиску. HippoRAG 2 (arXiv:2502.14802) целится именно в этот провал.
Вики отличается тем, что результат компиляции — обычный markdown. Файлы, которые человек может открыть, отредактировать и прочитать. Системы памяти прячут артефакт в базу данных, граф-системы — в кластерное дерево или PageRank-скор. Когда что-то идёт не так, вики ломается у тебя на виду. Остальные ломаются за стеной абстракции, и ты узнаёшь об этом по качеству ответов, а не по состоянию хранилища.
4. Когда вики не подходит
Вики не всегда правильный ответ. Четыре места, где она проигрывает: три конкретных, одно пока подозрение.
Масштаб. По моему опыту, ниже примерно 50 000 токенов (граница мягкая и зависит от того, чьё окно контекста оплачиваешь) корпус целиком помещается в контекстное окно, и вики проигрывает полному контексту. Запускать компрессию раньше — значит платить за то, что модель и так может обработать целиком. Верхняя граница тоже описана в гисте: Karpathy оценивает рабочий диапазон в сотни источников и несколько сотен страниц, выше чего плоский markdown-индекс перестаёт работать как каталог и паттерну приходится отращивать иерархию или эмбеддинг-слой.
Накопление ошибок. Karpathy называет этот режим в оригинальном гисте: ингест возвращает результаты обратно в вики, обновления на частичном контексте упускают зависимости, а компрессия теряет нюансы, и восстановить их нельзя. Петля замыкается через вход ингеста. Проход читает существующие страницы вики вместе с новым источником, поэтому слегка ошибочный саммари, уже попавший в корпус, становится авторитетом для следующего ингеста, и ошибка оказывается внутри корпуса к моменту, когда линт добирается до неё. Самое неприятное: такая ошибка выглядит как нормальный текст. Линт тут штатное лекарство. Он ловит противоречия и сирот-страницы дёшево, но тихо ошибочный саммари ему не виден, если ничто ниже по потоку не замечает расхождения. Это уже ломалось публично. HippoRAG переписал свою индексацию во второй версии, потому что первая теряла контекст и при ингесте, и при инференсе. LazyGraphRAG — признание, что предварительная суммаризация GraphRAG тратила вычисления на документы, до которых запросы так и не добрались.
Точные формулировки и несколько авторов. Регулируемый контент, завязанный на конкретные формулировки, проигрывает, когда вики их перефразирует, — а обычный векторный RAG по оригиналам сохраняет ту фразу, которую вики потеряла. Многоавторская координация давит с другой стороны: Collaborative Memory (arXiv:2505.18279) накручивает над общей памятью типизированные read/write-разрешения, чтобы у каждого пользователя был свой срез — механика, без которой одноавторская вики спокойно обходится.
Тихое гниение (подозрение, не диагноз). Без временно́й метки last_verified на каждом факте вики не может определить, какие из её утверждений ещё верны, а какие тихо устарели. Битемпоральные рёбра Zep чисто закрывают замещение — новый факт заменяет старый, ребро несёт срок годности — но тяжёлый случай другой: факт, который ничто в системе активно не перепроверяет. Для него общего ответа нет. Вики, за которой перестали следить, не падает с грохотом. Она начинает врать, и понимаешь это, когда в следующий раз открываешь страницу.
5. Что ломается первым, когда строишь вики
Вики-хранилище ломается в определённой последовательности. Правила для каждой поломки я узнал, сначала выкатив неправильный фикс.
Первая поломка: свободноформатные страницы решений не выживают, когда по ним начинают делать запросы. Писать решения без шаблона удобно ровно до момента, когда задаёшь вопрос типа «какие решения зависят от выбора остаться на Python» и обнаруживаешь, что depends_on есть в одних страницах, а в других нет, где-то списком, где-то прозой. Шаблоны нужны ровно для одного: они превращают кучу страниц в корпус, по которому можно строить запросы. Фронтматтер-схема должна проверяться на коммите, потому что добровольные схемы деградируют.
Вики-ссылки ломаются следующими. Можно неделями писать читаемые тексты, в которых решение упоминается по имени, но ни разу не линкуется. Потом пытаешься обойти граф. Граф готов наполовину: тело текста называет концепции, которых нет во фронтматтере, фронтматтер перечисляет страницы без обратных ссылок в теле, а структура ссылок определяется тем, что автор вспомнил в то утро. Перелинковать задним числом недолго, если есть обходчик графа. Без него дорого по вниманию. Правило, к которому я пришёл: ссылки и упоминания пишутся в одной правке. Страница, в теле которой упомянут концепт без ссылки, не проходит коммит. Так исчезает целый класс работы «потом перелинкую», потому что правило делает «потом» невозможным.
Мой первый инстинкт с решениями: ADR-традиция. Написал один раз, при изменении создаёшь новый документ, замещающий старый. Работает, когда решения редки, а запись имеет юридическую силу. В живой вики получается чаща. Два файла, и читатель должен знать, какой из них актуален. Лучше один файл на тему, текущее состояние наверху, а аудит-трейл вынесен из вики целиком, в append-only лог, где каждое изменение записывается строкой с таймстэмпом, плюс всё, что и так даёт version control. Для тех, кто учился писать решения в культуре комплаенса, это неудобно. Работает тем не менее.
Некоторые правила верны, но применены не в том месте. Первая версия моего inbox-хука блокировала любой коммит, если в staging-папке оставались необработанные сырые файлы. Правило здравое: staging не должен превращаться в кладбище. Но на коммите оно работало против меня: сессия, которая начинается с того, что ты кидаешь расшифровку в staging, а потом делаешь реальную работу, всю сессию будет содержать необработанный файл, и ни одного коммита сделать не получится. Перенос проверки с коммита на мёрдж-гейт решил проблему. Коммит, пуш и мёрдж — разные инструменты, и их смешение создаёт помехи.
Первый схема-линтер, который я написал, слишком доверял прозе. Он сканировал каждый токен в теле страницы и помечал всё, что выглядело как значение enum из фронтматтер-схемы. Придуманные значения он ловил правильно. Но он также ловил слово «active» посреди предложения и «draft» во фразе «первый черновик», и блокировал коммиты, с которыми всё было в порядке. Переписанная версия сканирует только код в бэктиках. Значения в бэктиках машиночитаемы, проза остаётся нетронутой. Линтер выжил потому, что стал узким.
Допущения под одного агента ломаются рано. Свод правил, выросший на модели прав, наборе инструментов и стиле вызова навыков одной платформы, не переносится, когда появляется второй агент. Натягивание интерфейса одного на свод правил другого маскирует структурные изменения, которые уже произошли. Выжившая форма: два равноправных свода правил и хук, отклоняющий коммиты при расхождении зеркал. Каждый навык пишется под оба свода в одной правке. Цена на навык выше. Зато любой из агентов может подхватить хранилище с нуля и работать с ним, и это оказывается важнее, чем ожидалось, когда работа должна пережить конкретную CLI-сессию.
На этапе закалки хранилища метаданные итерируются быстрее контента. Файлы правил, документы схемы, лог аудита: это самые редактируемые артефакты, а отдельные страницы решений нет. Поначалу это выглядит как антипаттерн — управление, меняющееся быстрее управляемого корпуса, противоречит интуиции, — а потом перестаёт. Контент накапливается тихо. Правила вокруг контента эволюционируют быстро, потому что реальные требования проявляются только тогда, когда реальный контент уже есть. Когда метаданные перестают меняться, хранилище либо закалилось, либо умерло.
Хорошего способа определить, становится ли вики лучше, у меня нет. Скорость добавления легко измерить, но она говорит не о том, о чём хотелось бы. Публичные бенчмарки задают другой вопрос: LongMemEval (arXiv:2410.10813) покрывает пять способностей памяти на длинных чатах, LOCOMO (arXiv:2402.17753) тестирует multi-session-память в диалогах, DMR из MemGPT (arXiv:2310.08560) оценивает multi-session-recall. Ни один не спрашивает того, что меня интересует — возвращает ли один и тот же запрос через полгода на том же эволюционирующем корпусе согласованный ответ — и статья Zep по DMR (arXiv:2501.13956) признаёт, что вопросы там достаточно неоднозначны, чтобы высокий счёт отражал навыки инференса LLM, а не точность памяти.
Ни один не измеряет консистентность во времени — один и тот же вопрос, заданный в разные моменты эволюции корпуса. Метрики достоверности суммаризации существуют, и ни один отчёт по системам памяти их не использует. Коммит-хуки ловят механическое: нарушения схемы, битые ссылки, противоречия. Тихая регрессия обнаруживается в следующий раз, когда открываешь страницу. Или не обнаруживается.
Неудобная часть этого подхода в том, что он звучит как оверхед. Стоимость поддержания заплачена заранее в шаблонах, схеме, цепочках хуков и форме append-only лога, а стоимость каждого коммита после этого близка к нулю. Длинная встреча превращается в дюжину пре-линкованных страниц решений за время одного ингест-прохода, потому что обходчики графа и схема делают ту работу, которую автор делал бы руками. Снаружи не видно, что всё в хранилище уже прошло через валидацию к моменту, когда читатель до него добирается. Но это верно не для каждой правки. Необратимые правки по-прежнему требуют записи в логе с моим именем. Поле decided_by во фронтматтере решения всегда заполняется человеком; агенты его не трогают. Спорные утверждения остаются на месте, контраргументы добавляются ниже, молчаливая перезапись исключена.
6. Что строить и когда
Выбор между RAG и вики — выбор, где платить. RAG быстро разворачивается, стоит копейки на запрос и упирается в стену, когда корпус вырастает настолько, что геометрия извлечения перестаёт помещаться. Вики требует больше на ингесте и меньше на запросе, лучше держит повторяющиеся вопросы к тому же материалу и вознаграждает того, кто её ведёт. Реальные системы обычно держат оба слоя: векторный поиск по неизменяемым источникам для точного recall, скомпилированную вики для синтеза по конкретному проекту.
Общее у режимов сбоя из этой статьи — где платят за вычисления. Перенос с момента запроса на момент ингеста и есть та самая ставка. Во что превратится артефакт — markdown-страницы, типизированные рёбра темпорального графа, заранее посчитанные саммари сообществ — зависит от того, для чего он нужен. Вики читает человек; граф запрашивает система. Оба ниже по течению от одного решения: компилировать один раз, читать много.
Аккуратного финала у меня нет. Вики, которую я построил, частично сгниёт в местах, куда я перестану возвращаться, а хуки продолжат ловить нарушения схемы, пока тихие саммари будут дрейфовать. Вот компромисс, на который идёт паттерн: никакой гарантии долговечности, только форма сбоя, которая лежит в файле, открываемом человеком. Метрика, которую хотелось бы иметь — один и тот же запрос, тот же корпус, через полгода, совпадают ли ответы — ни в одном бенчмарке пока не измеряется, так что до тех пор сигнал прежний: следующий раз, когда я открою страницу и поморщусь от того, что там написано.