RAG breaks earlier than people think
1. RAG breaks earlier than people think
You can feel the ceiling before you can measure it. At a few hundred thousand documents, a well-tuned vector index starts returning near-misses on queries it answered perfectly at a few thousand. You add a reranker and the top-1 moves back. You add hybrid search and the long tail gets better. Then you keep growing and the failures come back. Same kind, just harder to reproduce. Most teams read this as tuning work. Weller et al. (ICLR 2026) offer a different explanation: a single-vector retriever has a representational ceiling, and past it no amount of downstream cleverness compensates.
My own stack hit that ceiling before I could read the explanation for it, and the wiki that replaced it started as a reaction rather than a plan.
Part 1 walks the places plain RAG breaks, with citations. Part 2 is the architectural alternative — Karpathy’s LLM Wiki — and why it reframes the pipeline around compilation rather than retrieval. Part 3 is other systems doing the same move in different shapes (memory agents, graph RAG, HippoRAG). Part 4 is where the wiki is the wrong answer. Part 5 is what breaks first when you actually build one, from shipping a vault for an AI infrastructure team.
Weller et al. (arXiv:2508.21038, ICLR 2026) state the ceiling as an inequality. For a corpus of documents with top- queries and score margin , the embedding dimension must satisfy . Below that bound, some top- combinations are representationally unreachable in the vector space. The bound works in one direction only: if the embedding dimension sits below the threshold for a given corpus size, no reranker, hybrid search, or prompt engineering recovers the missing combinations. The geometry is already wrong.
The failures that follow cluster into three layers. Geometry (the ceiling above) is structural: no tuning moves it. Chunking and context utilisation are budget problems: careful preprocessing helps, but the budgets themselves are shrinking. Attention and hard negatives are generator failures: better prompts help, until the prompts stop mattering. Geometry can’t be tuned away. The other two layers respond to engineering effort.
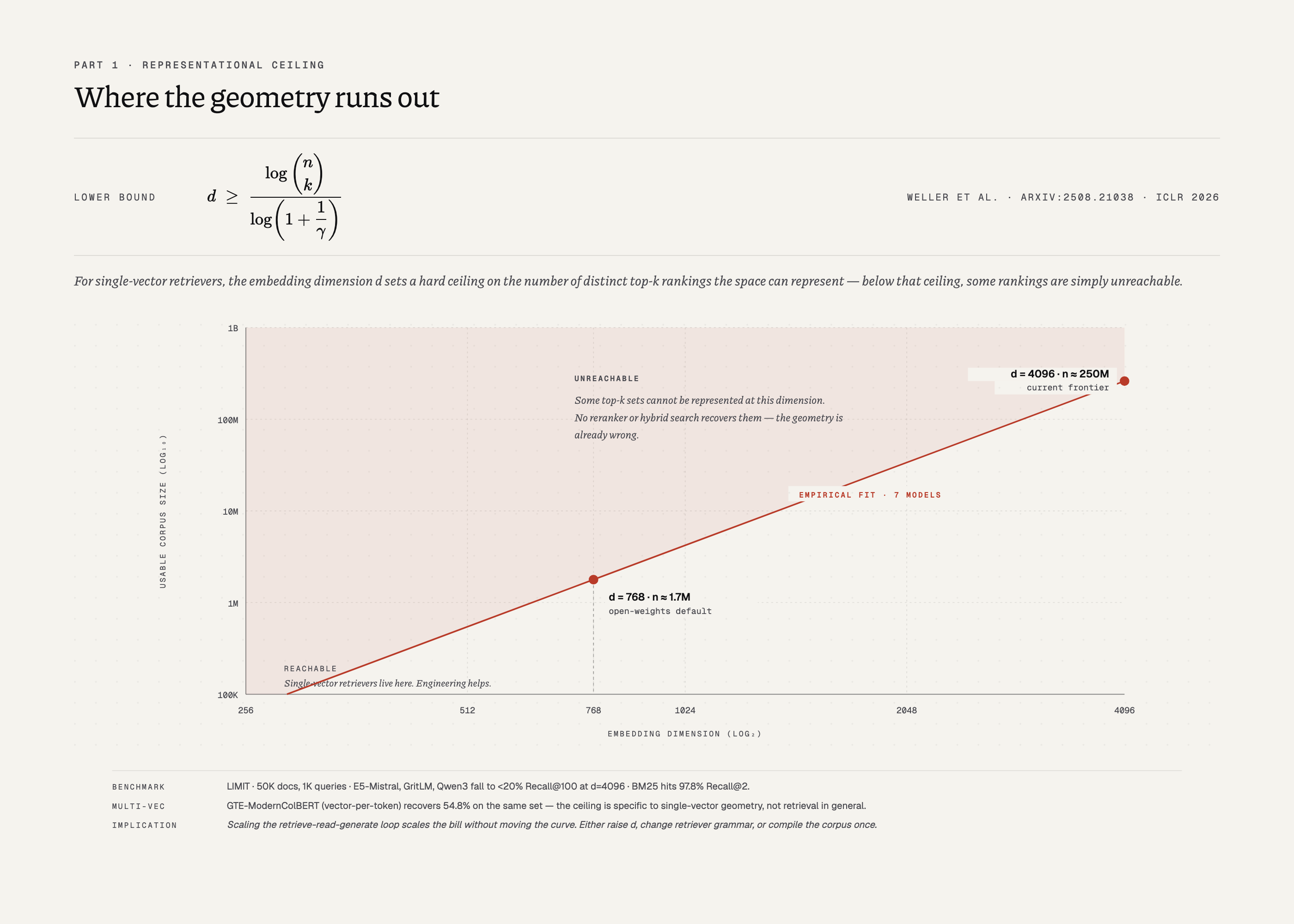
The empirical fit across seven models puts the usable corpus ceiling around 250 million documents at 4096 dimensions, and around 1.7 million at 768, still the common open-weights default. Above those sizes, some top- sets sit outside the span of any vector the retriever can produce.
Most benchmarks live inside those budgets and never probe the edge. LIMIT does. Fifty thousand documents, one thousand queries, sentences like “Jon likes apples”. E5-Mistral, GritLM, Qwen3 (the 2025 state of the art) land below 20% Recall@100 at 4096 dimensions on that set. BM25 hits 97.8% Recall@2. GTE-ModernColBERT, which keeps a vector per token rather than one per document, hits 54.8%. The failure sits in the single-vector geometry. A training-time embedding represents only a finite number of distinct top- sets, and when a query lands outside that set, nothing further in the pipeline compensates.
Chunking matters about as much as the model choice. Vectara’s 2025 study (arXiv:2410.13070) asks whether semantic chunking justifies its cost and finds that in most settings it doesn’t beat fixed-size chunking on F1@5 — the retrieval wins on recall, the generator loses on local context, and the two cancel. The failure is the common one: chunks small enough to retrieve precisely are too small for the generator to answer from.
Over half the retrieved snippets can be dropped without harming answer quality (arXiv:2511.17908). Prior work the paper builds on — RULER and the Context Rot studies — pegs the useful slice of a 128k-token context at 10-20% of what’s nominally there. The model skims.
Position bias is architectural. The MIT analysis in arXiv:2502.01951 sketches the mechanism: causal masking accumulates attention on early tokens through every layer, and rotary positional embeddings add a long-term decay to the score. Independent empirical work on long contexts (RULER, Context Rot) confirms the shape in practice — middle-of-context evidence is under-weighted, and longer windows don’t buy more attention; the extra tokens land in the zone the model already skips.
Hard-negative documents (the near-miss cases a good retriever is designed to surface) degrade end-to-end accuracy; arXiv:2401.14887 shows the mirror-image result, that random unrelated documents improve accuracy by up to 35%. The U-curve of answer quality against retrieved chunk count is OP-RAG’s core finding (arXiv:2409.01666). Fixing one failure mode surfaces the next.
Contextual Retrieval rewrites chunks with surrounding context before embedding: 35% failure reduction for embeddings alone, 49% when paired with BM25, 67% with a reranker on top. GraphRAG prioritises query-focused summarisation at indexing costs high enough that Microsoft itself shipped LazyGraphRAG as a cheaper follow-up, matching quality at roughly 1/700 the per-query cost. Self-RAG and CRAG move retrieval policy into the model itself. None of them change the basic loop: embed, search, read, generate, repeat. Once per question, paying the full cost again.
RAG is the correct first answer to “how do I ground an LLM in my data.” For a prototype, a proof of concept, a first integration, it works cheaply and buys you the shape of the problem. It breaks once you try to run a product on it. The embed-search-read-generate loop pays the full retrieval cost on every question and caps out where the geometry does, so scaling the loop scales the bill without moving the ceiling.
Two branches. One keeps optimising the query-time loop: better rerankers, late interaction, hybrid search, learned retrieval policies. Most public work is there. The other compiles the corpus once into something the model can read directly. Pay the work upfront, when the source comes in.
All of these failures share one assumption: the corpus stays raw, and the model re-derives its understanding of it on every query. The alternative is to compile the corpus once, into an artefact the model can read directly, and pay the cost at ingest instead of at query time. Karpathy posted a gist in April 2026 calling this second branch an LLM Wiki. What follows is what that means architecturally, and three very different systems that have already shipped it.
2. The wiki reframes the loop
The wiki is a persistent, compounding artifact. Instead of just retrieving from raw documents at query time, the LLM incrementally builds and maintains a persistent wiki.
I read this the first time on a Sunday and reread it twice looking for where the hard part was. The mechanics fit on one page.
The wiki has three layers.
- Raw sources at the bottom: PDFs, transcripts, pasted notes, web clips. Immutable once saved.
- The wiki in the middle: markdown pages the LLM writes, one per concept or decision, linked with wikilinks.
- The schema on top: CLAUDE.md, AGENTS.md, whatever file states what the wiki is for. The LLM reads it before every action.
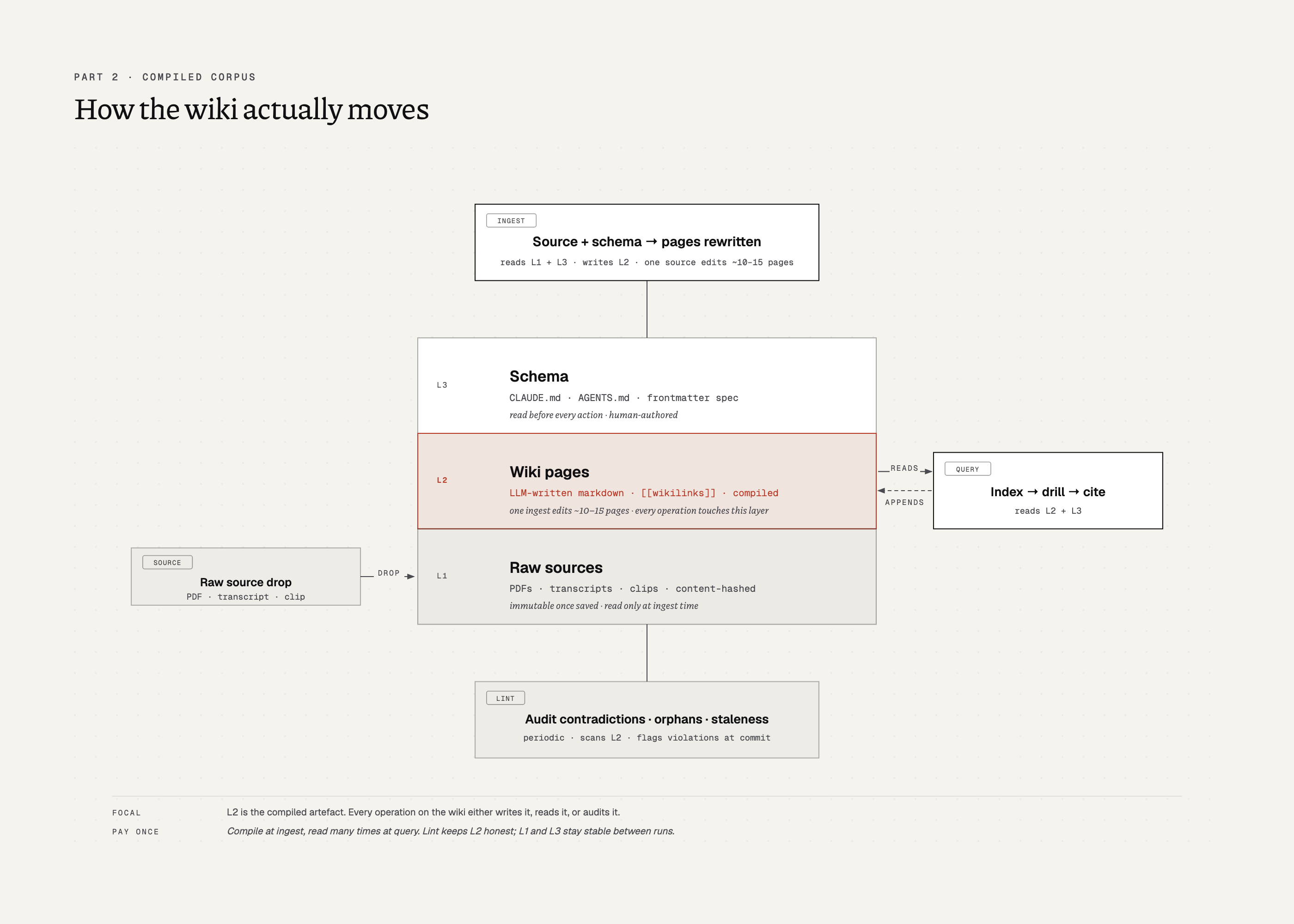
Ingest does the actual rewriting. A source comes in, the LLM reads it against the schema and the index, and edits whichever pages the source touches, often ten or fifteen at once.
Query looks lighter on paper: read the index, drill into a few pages, answer with citations. In practice query also writes back, because an answer worth keeping turns into a new page, and a query can kick off a small secondary ingest to save it.
Lint is the background pass and the unresolved design question. It walks the wiki for contradictions, stale claims, orphan pages, and missing cross-references. Nobody agrees on when it runs, how aggressive it should be, or what it does when it finds something. Every shipped implementation picks its own answers; mine (frontmatter schema validation at commit time, a linter that only flags values in inline code, append-only logs) are in Part 5.
Retrieval is incidental in this model. index.md, a plain markdown catalogue maintained by the LLM itself, works at the scale most projects actually live at (hundreds of sources, a few hundred pages) and removes the need for an embedding stack entirely. You can add vectors later if the catalogue stops scaling. You start without them.
Compilation is the analogy. Each ingest is an incremental build over the previous artefact rather than a fresh pass. A single source typically touches several pages, and a page integrates evidence from several sources. At query time the generator reads compiled pages instead of raw text. Two lines in the gist carry most of the argument: “The human’s job is to curate sources, direct the analysis, ask good questions, and think about what it all means. The LLM’s job is everything else,” and “Most people abandon wikis because maintenance burden grows faster than value. LLMs don’t get bored.”
The first operation I tried to think through was lint, because I knew the first wiki I’d write would be wrong in ways I wouldn’t notice. Karpathy’s version is informal: run it periodically, read the report. He cites Vannevar Bush’s Memex (1945) as prior art for the whole pattern: a private, curated knowledge store with associative trails between documents, maintained by the person who used it.
The original spec ignores time. It treats every piece of content as equally true forever.
A lifecycle extension bolts onto the wiki. Facts carry a confidence score that decays over time unless refreshed (roughly the shape of Ebbinghaus’s forgetting curve) and resets on access, so claims nobody revisits grow less trusted automatically. When a claim changes, the new version supersedes the old one and carries a pointer back. The old version stays in place. Edges between pages are typed: uses, depends on, contradicts, supersedes.
It’s shipped at least three times, on very different substrates.
The shoestring version
Bash scripts against an Obsidian vault. A handful of agents, a set of skills, no build system except a contract around what tools each agent can touch. Every agent declares its primitives from a fixed set — one might be allowed to read pages and write the index, but forbidden to touch the schema file. Anything off the list fails before the skill ever runs. This design moves almost nothing to ingest time. The agents integrate on demand, and query-time work stays close to what you’d pay without the wiki. What breaks first is cross-platform skew: the same vault driving several LLM CLIs only stays coherent because the contract is narrow enough to hide their differences.
The heavy version
Tauri runtime, React front end, installable binaries. This version packs the whole thing into a desktop application and moves the most work to ingest. A source arrives, the pipeline runs a two-step chain-of-thought pass: analysis against the current purpose file and index, then generation of typed FILE blocks for everything the source touches. Ingest is keyed by content hash. Re-ingest is a no-op. Jobs run through a persistent crash-recoverable queue with retry so an interrupted ingest resumes instead of being lost. Optional vector search bolts onto the catalogue at the end. The ingest cost buys one thing: the wiki is already compiled by the time you open the app.
The portable version
A plugin: one Agent Skills definition, every major LLM CLI, no build step. A single small markdown file — the hot cache — holds it together, a few hundred words of the recent context of work in progress. Session start reads it. Session end updates it. The gap between those two reads is where continuity lives. Without it, every new session opens with amnesia. The cache goes stale if work shifts between contexts without a session-end update. Nothing detects the staleness.
3. Other shapes of the same move
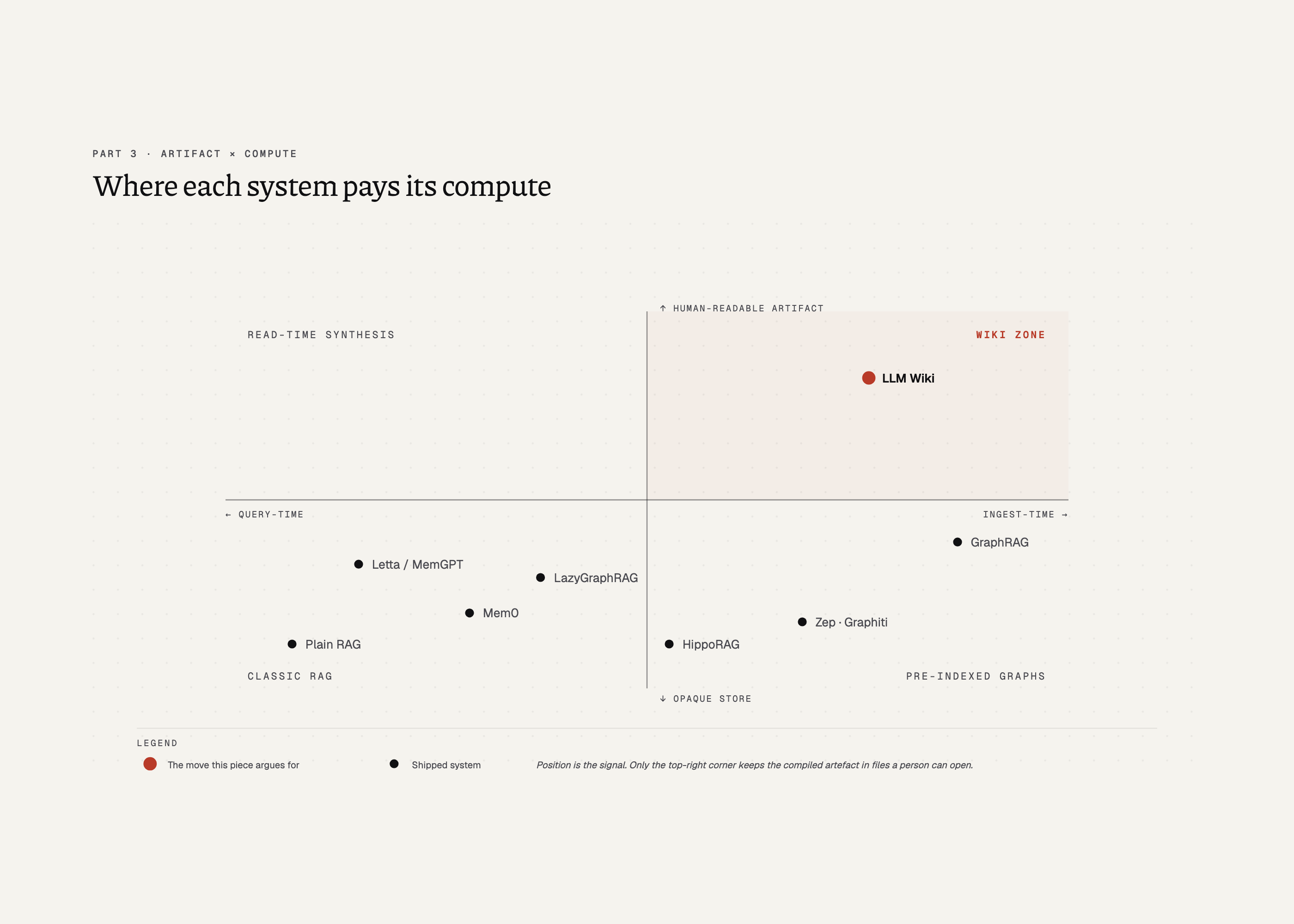
The three systems in Part 2 all commit to the wiki shape: compile the corpus into markdown, let the human read the artefact. Others solve the same problem from different angles, and what they keep as the artefact says as much as their mechanics. Four families keep coming up.
Memory agents: Letta and Mem0
Letta (formerly MemGPT, arXiv:2310.08560) pages between main context, recall, and archival tiers by function call. Mem0 extracts entity-and-relation facts from every message, resolves conflicts, and writes to a hybrid vector-plus-graph backend; on LOCOMO it reports 66.9% accuracy against OpenAI memory’s 52.9% (Mem0 paper, arXiv:2504.19413), closing the gap to a full-context baseline to about six points.
Temporal graphs: Zep
Zep does the most interesting thing in this group. Its graph layer, Graphiti (arXiv:2501.13956), timestamps every edge with valid_at and invalid_at. Old beliefs stay in the store with an explicit expiry. A query can ask what the system thought last Tuesday. That’s the same problem the wiki’s lifecycle extension tries to solve, from the database side.
Graph RAG: Microsoft’s line
Graph-RAG starts expensive. Microsoft’s GraphRAG (arXiv:2404.16130) extracts an entity graph, runs Leiden clustering, and pre-writes community summaries at every level — indexing cost that becomes prohibitive on anything larger than a single book. Microsoft’s own follow-up, LazyGraphRAG (Microsoft Research blog, November 2024), drops the pre-summarisation and matches quality at more than 700 times lower per-query cost. That’s Microsoft Research admitting its own indexing pipeline was wasteful. LightRAG (arXiv:2410.05779) arrives nearby: entity-and-relation extraction at ingest, dual-level retrieval, lightweight per-query profile by design.
Concept graphs: HippoRAG
HippoRAG (arXiv:2405.14831) is the strangest. It turns the corpus into a concept graph of noun phrases and answers queries by running Personalized PageRank. Single-step multi-hop reasoning. The v1 failure was entity-centric indexing: the concept graph stripped surrounding context at both ingest and inference, which hurt plain factual recall. HippoRAG 2 (arXiv:2502.14802) targets that gap.
Letta, Mem0, Zep, and every graph system above store their artefact in a database or index the reader never opens. The wiki is just markdown files.
4. When the wiki doesn’t fit
A wiki isn’t always the right answer. Four places it loses: three concrete, one still a suspicion.
Scale. In my experience, below roughly 50,000 tokens (a soft threshold that depends on which model’s window you’re paying for) the corpus fits inside a modern context window and the wiki loses to full-context. The wiki starts being worth building around the point where the context stops holding the whole corpus, which is also the point where you have to start maintaining the compression. The upper bound is hundreds of sources and a few hundred pages, above which the plain markdown index stops scaling as a catalogue, and the pattern has to grow its own hierarchy or an embedding layer to keep working.
Error accumulation. Ingest feeds back into the wiki. Karpathy is explicit about this: partial-context updates miss dependencies, compression drops nuance you can’t recover. The feedback works through the ingest input. A pass reads existing wiki pages alongside the new source, so a slightly wrong summary already in the corpus becomes the authority the next ingest integrates against, and the error is inside the corpus by the time lint runs.
Lint is the prescribed fix. It catches contradictions and orphan pages cheaply. What it can’t see is a quietly wrong summary that nothing downstream notices. Two shipped systems have already corrected for this in public. HippoRAG 2 (arXiv:2502.14802) explicitly rewrites v1’s entity-centric indexing because it lost context during both ingest and inference. LazyGraphRAG is Microsoft Research admitting, in a product blog, that GraphRAG’s upfront summarisation was prohibitive and wasted compute on documents the queries never touched.
Specific wording and multi-author corpora. Regulated content that relies on specific wording loses when the wiki paraphrases it. Plain vector RAG over the originals preserves the phrase the wiki dropped. Multi-author coordination breaks things differently. Collaborative Memory (arXiv:2505.18279) layers typed read/write permissions over shared memory to keep per-user views isolated, machinery a single-author wiki doesn’t need.
Silent rot (suspicion, not diagnosis). Without a last_verified timestamp on each fact, the wiki can’t tell which claims still hold and which have quietly gone stale. Zep’s bi-temporal edges handle supersession cleanly — a new fact replaces an old one and the edge carries the expiry — but the harder case is the fact nothing in the system actively rechecks. No general answer exists for that. A wiki that stops being maintained doesn’t fail loudly. It starts lying, and you find out the next time you read the page.
5. What breaks first when you build a wiki
When you build a wiki-shaped knowledge base it fails in a specific order. I learned the rules for each failure by shipping the wrong fix first.
Free-form decision pages don’t survive being queried across. Writing decisions without a template feels fine, right up until you ask a question like “what decisions depend on the choice to stay on Python” and you realise depends_on is in some pages and not others, sometimes as a list and sometimes as prose. Templates matter for one reason: they turn a pile of pages into a corpus you can query across. A frontmatter schema has to be enforced at commit time, because voluntary schemas decay.
Wikilinks break next. You can write perfectly readable prose that names a decision and never links to it. You can do that for weeks. Then you try to walk the graph. The graph is half there: body prose names concepts the frontmatter doesn’t, frontmatter names pages the body doesn’t, and the link structure is whatever an author happened to remember that morning. Retroactive relinking is cheap in wall time if you have a graph walker and expensive in attention if you don’t. The rule I ended up with is that references and links go into the page in the same edit. A page body that mentions a named concept without linking to it fails the commit. That removes the whole category of “I’ll relink later” work.
My first instinct with decision pages was the ADR tradition: write once, supersede with a new document when the underlying call changes. That works when decisions are rare and the record is legal. In a live wiki it turns the corpus into a thicket. You end up with two files, and a reader has to know which one is live. The better shape is one file per topic, current state at the top, and the audit trail moved out of the wiki entirely, into an append-only log that records every change as a timestamped line, plus whatever version control already gives you. This is uncomfortable for anyone who learned decision-writing from compliance culture. It works anyway.
Some rules are right and enforced in the wrong place. The first version of my inbox-policing hook blocked any commit that left unprocessed raw files in a staging folder. The rule is sound, because staging should not turn into a graveyard. Enforcing it at commit time was the wrong move: a session that drops a transcript into the staging folder and then does real work will have an unprocessed raw file for the whole session, which means no commits at all. Moving enforcement from commit time to the merge gate fixed it. Commit-time, push-time, and merge-time aren’t the same tool.
The first schema linter I wrote was too trusting with prose. It scanned every token in page bodies and flagged anything that looked like an enum value from the frontmatter schema. It caught invented values correctly. It also flagged the word “active” in a sentence, and “draft” in the phrase “first draft”, and blocked commits that were completely fine. The rewrite only scans inline code spans. Values wrapped in backticks are machine-readable, and prose is left alone. Making the linter narrow is what kept it from being turned off.
Single-agent assumptions break early. An agent rulebook that grew up against one platform’s permission model, tool surface, and skill invocation style won’t port when a second agent arrives. Shimming one agent’s interface onto the other’s rulebook papers over a structural change that has already happened. The shape that survives is two peer rulebooks and a hook that refuses commits when the mirrors drift. Every skill gets written against both rulebooks in the same edit. Cost per skill is higher. The payoff: either agent can pick up the vault cold. That matters more than expected once the work has to outlast a particular CLI’s session.
During the hardening phase, metadata iterates faster than content. The rule files, the schema documents, the audit log: those are the most-edited artefacts. At first this looks like a smell. Governance churning more than the corpus it governs is counter-intuitive. Then it stops looking like a smell. Content accumulates quietly. The rules around content evolve fast, because real requirements surface only once real content exists. The day the metadata files stop churning is the day the vault either hardened or died.
The uncomfortable part of this approach is that it sounds like overhead. The maintenance cost is paid upfront in templates, schema, hook chains, and the shape of the append-only log, and the per-commit cost afterwards is close to zero. A long meeting becomes a dozen pre-linked decision pages in the time it takes to run the ingest pass, because the graph walkers and the schema do the work the author would otherwise do by hand. Not every edit, though. Irreversible ones still require a timestamped log entry that names me. The decided_by field in a decision’s frontmatter is always a human name; the agents never fill it. Contested claims stay in place with counter-evidence added below them, never silently overwritten.
I don’t have a good way to tell whether the wiki is improving. Add-rate is easy to measure and doesn’t mean what I’d like it to mean. The public benchmarks ask a different question than I want answered: LongMemEval (arXiv:2410.10813) covers five memory abilities across long chat histories, LOCOMO (arXiv:2402.17753) tests multi-session conversational memory, and DMR from MemGPT (arXiv:2310.08560) scores multi-session recall. None of them asks the question I care about — whether the same query asked six months apart on the same evolving corpus returns a consistent answer — and Zep’s paper reporting on DMR (arXiv:2501.13956) admits the questions are ambiguous enough that a high score can reflect LLM inference skill rather than memory fidelity.
No published benchmark measures time-travel consistency: the same question asked at different points as the corpus evolves. Summarisation-fidelity metrics like FaithEval exist. No memory system paper reports using them.
What the commit hooks catch is mechanical: schema violations, broken wikilinks, contradictions flagged by the narrative-schema linter. Silent regression, a quietly wrong summary that nothing in the system notices, shows up the next time I open the page. Or it doesn’t.
6. What to build, and when
The choice between RAG and a wiki is a choice about where to pay. RAG stands up fast, costs little per token, and caps out when the corpus gets large enough that the retrieval geometry runs out of room. A wiki costs more at ingest and less at query, holds up better under repeated questions on the same material, and rewards the human who maintains it. Real systems tend to ship both layers: vector search over immutable sources for precise recall, a compiled wiki for synthesis across a specific project.
What the failure modes in this piece share is where compute gets paid. The move from query time to ingest time is the underlying bet. Whether the output lands as markdown pages, typed edges in a temporal graph, or pre-computed community summaries depends on what the artefact is for. A wiki is read by humans; a graph is queried by systems. Both sit downstream of the same decision: compile once, read many.
I don’t have a neat ending. The wiki I built will rot in places I stop re-reading, and the commit hooks will keep catching schema violations while silent summaries drift. That’s the trade the pattern makes: no durability guarantee, just a failure mode that lives in a file a person can open. The measure I’d want — same query, same corpus, six months apart, do the answers agree — isn’t something any benchmark reports on yet, so for now the signal is the next time I open a page and flinch at what it says.